
What is the Project?
Dynamic Programming (DP) is an effective method for solving complex problems by breaking them down into sub-problems. The solutions to those sub-problems are then combined to solve the overall complex problem.
In Reinforcement Learning (RL), DP solves planning problems for finite Markov Decision Processes (MDPs). Within this project, I will provide three strategies that solve the same agent environment (MDP), OpenAI Gym's FrozenLake.
The Environment
FrozenLake is a 4x4 grid containing a total of 16 states, \(\mathcal{S} = \{0, 1, 2, \cdots, 15\}\). Agents can take one of four actions, \(\mathcal{A} = \{left, down, right, up\}\), and start in the top left corner (S), where they aim to reach the goal state (G) in the bottom right corner. They can move on any frozen surface (F) but must avoid falling into any holes (H). The goal state provides a reward of +1 and 0 otherwise. Furthermore, an episode ends when the agent reaches the goal or falls into a hole.
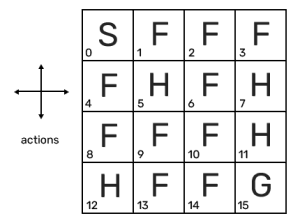
Figure 2.1 Depiction of the FrozenLake environment.
Solving the Environment
The environment was solved using Policy Iteration, Truncated Policy Iteration, and Value Iteration. Each variant uses a similar approach with slight differences, but all guarantee convergence to an optimal policy when applied to a finite MDP.
- Policy Iteration: uses a sequence of policy evaluation and improvement steps until the policy has converged to optimality. Firstly, policy evaluation focuses on estimating the state-value function by constantly performing a Bellman update. Next, policy improvement converts the estimate into an action-value function and maximises the actions taken to improve the policy.
- Truncated Policy Iteration: acts similarly to Policy Iteration but limits the evaluation step to a maximum number of iterations through the space state, reducing computational complexity.
- Value Iteration: acts like Policy Iteration but with a single evaluation step.
Results Comparsion
Every method achieved the same optimal policy and state-value function, but Value Iteration proved superior due to converging faster.
| Type | Time Taken |
| Policy Iteration | 0.3448 seconds |
| Truncated Policy Iteration | 0.2678 seconds |
| Value Iteration | 0.0809 seconds |